

前言
公司的采购系统中,有发票管理工具,里面可以做发票对账。具体的做法就是每次有一个新的供应商,我们的工程师就解析对应的发票PDF文件,但是每次都要花费很长时间,因此考虑了下,做了一个发票解析引擎。
发票结构
一般而言,发票有如下格式:
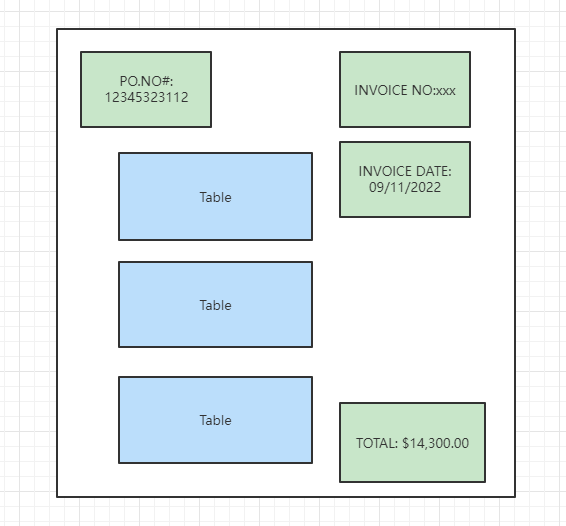
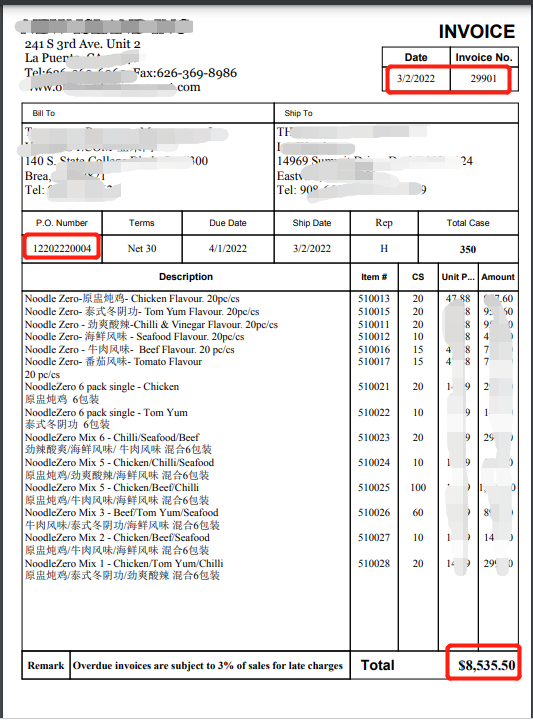
要获取的内容分为两类:
1、主体内容,包括发票单号、发票日期、PO(purchase order)号,以及总金额
2、列表详情,存在于Table中的数据,需要获取的列有: 个数(qty)、单价(price)、三方产品编号(vendorUpc)以及我们自己的编号(upc)
引擎思路
现有情况:
- 首先,使用的是Java语言(毕竟后台都是Java系的)。
- 然后,使用spire-fire或者pdfbox进行解析
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf.free</artifactId>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
</dependency>
这两个解析工具有自己的特点:
spire是尽量保证格式,但是可能会出现table中相邻列的数字粘连在一起的情况
pdfbox无法保证原始格式,但是一般情况下,table中的相邻数字列不会粘连在一起
- 再然后每次来一个发票,就有后台的同学从头到尾解析一边,大量的重复代码,以及各种特殊情况处理,经常一张发票需要解析
1~2天才能完成,而且还要重新发布上线。
那么如何改进呢?
我的思路是做一个统一的解析引擎,将所有的信息自顶向下做成解析规则,依赖这个引擎解析出来即可,每次有一个新的发票格式的时候,只需要给出对应的一批规则即可,可以在管理后台上进行配置,无需修改代码以及重复上线步骤。
下面是整个引擎框架思路:
1、根据发票结构,分为主体信息(PO号,发票号,发票日期,总金额等)和table信息(主要包括单价、数量、供应商编号vendorUPC以及自己的)
2、发票主体的解析,每个内容都给出一个对应的规则,使用正则表达式的分组捕获
3、table信息解析包含以下内容:
- table起始的标记信息(正则表达式)
- table结束的标记信息(正则表达式)
- row起始的标记信息(正则表达式)
- row结束的标记信息(正则表达式)
- qtyIdx(一行内容使用空格切分后,代表数量的那个索引下标)
- priceIdx(同qty, 单价的索引下标)
- upcIdx(同上,自己商品编号的索引下标)
- vendorUpcIdx(同上,商家自己的编号的索引下标)
不过,在使用过程中,发现很多特殊情况,单纯的靠正则表达式或者下标索引,很难真的得到信息,因此我这边加入了逻辑功能(依靠内嵌的JavaScript代码)
注意 JDK15之后内置的JS引擎Nashorn被移除,我们可以手动导入
<dependency> <groupId>org.openjdk.nashorn</groupId> <artifactId>nashorn-core</artifactId> <version>15.4</version> </dependency>
最终的规则内容如下:
@Data
@Builder
public static class ParseRule {
/**
* 提取pdf文本的工具, 二选一: pdfbox spire。不填默认是spire
*/
String textExtractTool;
/**
* 获取发票单号的regex。 查询上下文是整个PDF文本。
*/
String invoiceNumber;
/**
* 获取发票单号的js语句。注意:只有invoiceNumber没有配置的时候才会使用此内容,可以使用 $pdf 参数,类型是字符串,内容是当前pdf的全部文本
*/
String invoiceNumberByJs;
/**
* 获取发票日期的regex. 查询上下文是整个PDF文本。
*/
String invoiceDate;
/**
* 发票日期的js,使用情况同invoiceNumberByJs
*/
String invoiceDateByJs;
/**
* 获取PO号的regex. 查询上下文是整个PDF文本。
*/
String reference;
/**
* 获取PO号的js,使用情况同invoiceNumberByJs
*/
String referenceByJs;
/**
* 获取总金额的regex. 查询上下文是整个PDF文本。
*/
String totalAmt;
/**
* 获取总金额的js,invoiceNumberByJs
*/
String totalAmtByJs;
/**
* 发票日期的格式,需要解析的时候做转换使用,比如 MM/dd/yyyy or yyyy/MM/dd
*/
String invoiceDateFormat;
/**
* 表开始的regex. 查询上下文是整个PDF文本。
*/
String tableStart;
/**
* 表结束的regex,查询内容是从tableStart开始的内容。
*/
String tableEnd;
/**
* 行开始的regex,查询上下文是 一个表 的内容(用tableStart, tableEnd截取的一个表的内容)
*/
String rowStart;
/**
* 行结束的regex,查询上下文是 一个表的内容 中,rowStart查询到的位置之后
*/
String rowEnd;
/**
* 获取商品数量的索引下标。 这里的上下文是 一行 (用rowStart和rowEnd规则解析出来的一行的内容),
* 将其去掉首位空格,并将里面的多个连续空格转为单个空格后,split(' ')之后的数组下表
* 注意,可以是 负数,类似python中的取法,即 -1表示最后一个, -2表示倒数第二个,以此类推
*/
String qtyIdx;
/**
* 如果qty这一列,仅通过 下标还不好取出来,或者得到最终结果,可以借助该 js内容来执行。
* 可以使用 $row 参数,类型是字符串,内容是当前行规整后(去掉首尾空格,多个连续空格转为单空格)的文本
*
* 注意:只有在qtyIdx没有内容的前提下,才会使用qtyByJs来解析
*/
String qtyByJs;
/**
* 获取price的索引下标。原理同qtyIdx
*/
String priceIdx;
/**
* price的js获取方式,原理同qtyByJs
*/
String priceByJs;
/**
* upc(即自己的的item number?)的索引下标 ,原理同qtyIdx
*/
String upcIdx;
/**
* upc的js获取方式,原理同qtyByJs
*/
String upcByJs;
/**
* vendorUpc(即供应商的item code等)的索引下标,原理同qtyIdx
*/
String vendorUpcIdx;
/**
* vendorUpc的js获取方式,原理同qtyByJs
*/
String vendorUpcByJs;
}
解析流程
下面是整体的解析流程
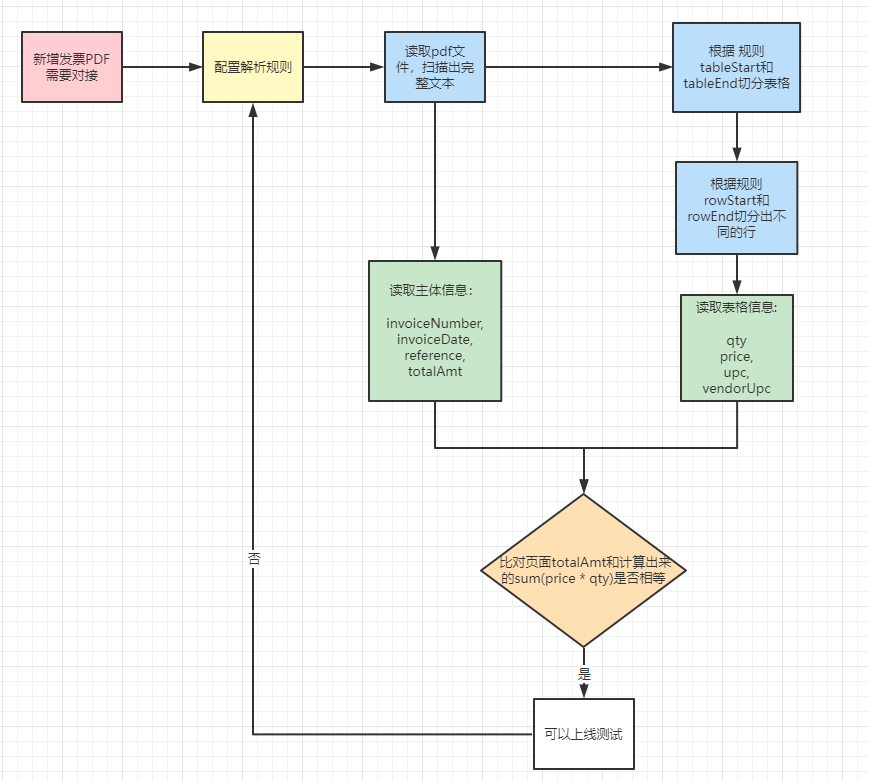
主体信息解析:
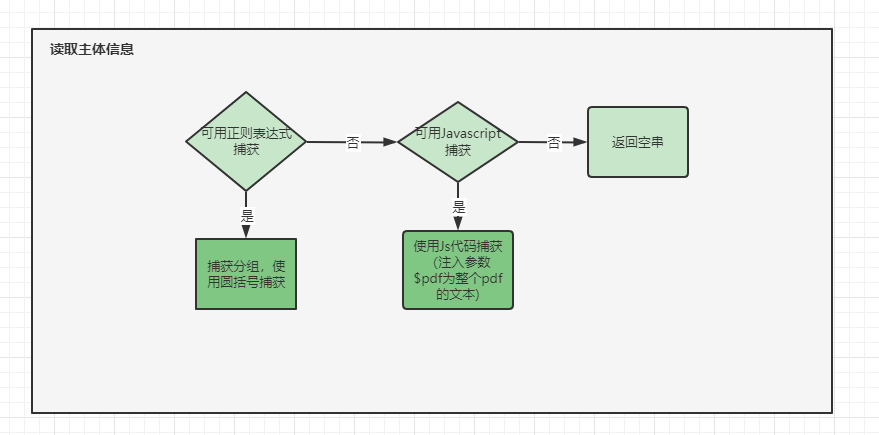
表格信息解析:
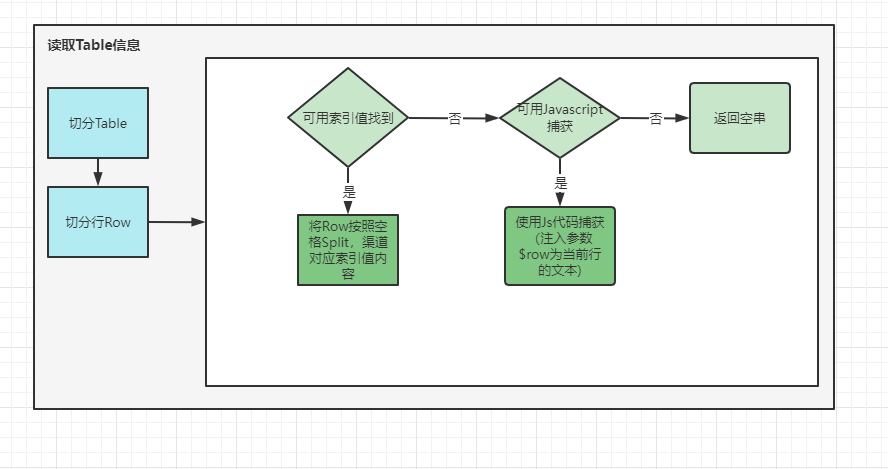
具体代码
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import lombok.Builder;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import javax.script.Bindings;
import javax.script.ScriptEngine;
import javax.script.ScriptEngineManager;
import javax.script.ScriptException;
import java.io.InputStream;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
@Slf4j
public class InvoiceParser {
static final String KEY_MAIN_INFO = "mainInfo";
static final String KEY_ITEMS = "items";
static final String KEY_INVOICE_NUMBER = "InvoiceNumber";
static final String KEY_INVOICE_DATE = "InvoiceDate";
static final String KEY_INVOICE_DATE_LONG = "InvoiceDateLong";
static final String KEY_REFERENCE = "Reference";
static final String KEY_TOTAL_USD = "TotalAmt";
static final String KEY_UPC = "upc";
static final String KEY_VENDOR_UPC = "vendorUpc";
static final String KEY_PRICE = "price";
static final String KEY_QTY = "qty";
static final String PDF_TOOL_PDFBOX = "pdfbox";
static final String PDF_TOOL_SPIRE = "spire";
static final String BINDING_KEY_PDF = "$pdf";
static final String BINDING_KEY_ROW = "$row";
private final String pdfUrl;
private final ParseRule parseRule;
private final String pdfContent;
private List<String> tableContentList = new ArrayList<>();
ScriptEngineManager scriptEngineManager = new ScriptEngineManager();
ScriptEngine engine = scriptEngineManager.getEngineByName("JavaScript");
Map<String, Object> mainInfoMap;
List<Map<String, String>> itemsInfoList;
public InvoiceParser(String pdfUrl, ParseRule parseRule) {
this.pdfUrl = pdfUrl;
this.parseRule = parseRule;
this.pdfContent = getPdfContent();
}
public String getPdfText(){
return this.pdfContent;
}
private String extractTextByPdfbox(InputStream inputStream){
try {
PDDocument document = PDDocument.load(inputStream);
PDFTextStripper stripper = new PDFTextStripper();
return stripper.getText(document);
}catch (Exception e){
log.error("Extract text by pdf box with error,", e);
return "";
}
}
private String extractTextBySpire(InputStream inputStream){
try {
PdfDocument doc = new PdfDocument();
doc.loadFromStream(inputStream);
StringBuilder sb = new StringBuilder();
Map<String, Object> res = new HashMap<>();
PdfPageBase page;
// 遍历PDF页面,获取每个页面的文本并添加到StringBuilder对象
for (int i = 0; i < doc.getPages().getCount(); i++) {
page = doc.getPages().get(i);
sb.append(page.extractText(true));
}
doc.close();
return sb.toString();
}catch (Exception e){
log.error("Extract text from pdf with exception", e);
return "";
}
}
private String getPdfContent() {
try {
URL url = new URL(pdfUrl);
URLConnection connection = url.openConnection();
connection.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
try(InputStream inputStream = connection.getInputStream()){
if(PDF_TOOL_PDFBOX.equals(parseRule.textExtractTool)){
return extractTextByPdfbox(inputStream);
}
return extractTextBySpire(inputStream);
}
} catch (Exception e) {
log.error("get content from pdf with exception", e);
return null;
}
}
public Map<String, Object> parse() {
Map<String, Object> parseResult = new HashMap<>(2);
try {
log.info("Parse start *************** pdf url is {}", pdfUrl);
log.info("Current parse rule is {}", parseRule);
// 获取基础信息,发票订单号、日期、PO号,总金额等
mainInfoMap = parseMainInfo();
parseResult.put(KEY_MAIN_INFO, mainInfoMap);
// 获取列表信息
itemsInfoList = parseTableInfo();
parseResult.put(KEY_ITEMS, itemsInfoList);
log.info("Check total result:{}", checkTotal());
log.info("Parse end *************** pdf url is {}", pdfUrl);
}catch (Exception e){
log.error("Parse with exception", e);
}
return parseResult;
}
private Map<String, Object> parseMainInfo() {
log.info("Parse main info start");
Map<String, Object> mainInfoMap = new HashMap<>(8);
try {
String invoiceNumber = parseInfoInPdf(parseRule.invoiceNumber, parseRule.invoiceNumberByJs);
String invoiceDate = parseInfoInPdf(parseRule.invoiceDate, parseRule.invoiceDateByJs);
Long invoiceDateLong = TimeTransUtil.tranTimeToLongByUsTime(invoiceDate, Constant.LA_TIME_ZONE, parseRule.invoiceDateFormat);
String reference = parseInfoInPdf(parseRule.reference, parseRule.referenceByJs);
String totalUsd = parseInfoInPdf(parseRule.totalAmt, parseRule.totalAmtByJs).replaceAll(",", "");
mainInfoMap.put(KEY_INVOICE_NUMBER, invoiceNumber);
mainInfoMap.put(KEY_INVOICE_DATE, invoiceDate);
mainInfoMap.put(KEY_INVOICE_DATE_LONG, invoiceDateLong);
mainInfoMap.put(KEY_REFERENCE, reference);
mainInfoMap.put(KEY_TOTAL_USD, totalUsd);
log.info("Parse main info end, result is: {}", mainInfoMap);
}catch (Exception e){
log.error("parse main info error,",e);
}
return mainInfoMap;
}
private List<Map<String, String>> parseTableInfo() {
List<Map<String, String>> parsedList = new ArrayList<>();
if (StringUtils.isNotEmpty(parseRule.tableStart) && StringUtils.isNotEmpty(parseRule.tableEnd)) {
// use regex
log.info("Parse table contents start");
parseAllTableContents();
log.info("Parse table contents end, tables count is {}", tableContentList.size());
}
for (String tableContent : tableContentList) {
log.info("Parse rows of one table start");
List<String> rowList = parseRows(tableContent);
log.info("Parse rows of one table end, rows count is {}", rowList.size());
for (String row : rowList) {
Map<String, String> rowDataMap = new HashMap<>(rowList.size());
String qty = parseField(row, parseRule.qtyIdx, parseRule.qtyByJs);
String price = parseField(row, parseRule.priceIdx, parseRule.priceByJs);
String upc = parseField(row, parseRule.upcIdx, parseRule.upcByJs);
String vendorUpc = parseField(row, parseRule.vendorUpcIdx, parseRule.vendorUpcByJs);
if (StringUtils.isNotEmpty(qty)) {
rowDataMap.put(KEY_QTY, qty);
}
if (StringUtils.isNotEmpty(price)) {
rowDataMap.put(KEY_PRICE, price);
}
if (StringUtils.isNotEmpty(upc)) {
rowDataMap.put(KEY_UPC, upc);
}
if (StringUtils.isNotEmpty(vendorUpc)) {
rowDataMap.put(KEY_VENDOR_UPC, vendorUpc);
}
parsedList.add(rowDataMap);
}
}
log.info("All table data parsed end, total size is {}", parsedList.size());
if (parsedList.size() > 0) {
log.info("The parsed items are:");
for(Map<String, String> item :parsedList){
log.info("{}",item);
}
}
return parsedList;
}
public boolean checkTotal(){
try {
BigDecimal total = new BigDecimal((String) mainInfoMap.get(KEY_TOTAL_USD));
BigDecimal calculatedTotal = BigDecimal.ZERO;
for (Map<String, String> item : itemsInfoList) {
calculatedTotal = calculatedTotal.add(new BigDecimal(item.get(KEY_PRICE)).multiply(new BigDecimal(item.get(KEY_QTY)))).setScale(2, RoundingMode.UP);
}
log.info("Total usd:{}, calculatedTotal:{}", total, calculatedTotal);
return total.compareTo(calculatedTotal) == 0;
}catch (Exception e){
log.error("Check total with exception",e);
return false;
}
}
private void parseAllTableContents() {
tableContentList = fetchContentBetween(pdfContent, parseRule.tableStart, parseRule.tableEnd, false);
}
private List<String> parseRows(String tableContent) {
List<String> rowList = fetchContentBetween(tableContent, parseRule.rowStart, parseRule.rowEnd, true);
return rowList.stream().map(row -> row.replaceAll("\\s+", " ").trim()).collect(Collectors.toList());
}
private String parseInfoInPdf(String ruleRegex, String ruleJs) {
if (StringUtils.isNotEmpty(ruleRegex)) {
Pattern pattern = Pattern.compile(ruleRegex);
Matcher matcher = pattern.matcher(pdfContent);
if (matcher.find()) {
return matcher.group(1);
} else {
log.warn("Can not find anything by regex: {}", ruleRegex);
}
} else if (StringUtils.isNotEmpty(ruleJs)) {
Map<String, String> params = new HashMap<>(1);
params.put(BINDING_KEY_PDF, pdfContent);
return parseJs(ruleJs, params);
}
return "";
}
private String parseField(String rowStr, String ruleIdx, String ruleJs) {
if (StringUtils.isNotEmpty(ruleIdx)) {
int index = Integer.parseInt(ruleIdx);
String[] fields = rowStr.split("\\s");
return fields[index >= 0 ? index : fields.length + index];
} else if (StringUtils.isNotEmpty(ruleJs)) {
Map<String, String> params = new HashMap<>(1);
params.put(BINDING_KEY_ROW, rowStr);
return parseJs(ruleJs, params);
} else {
return "";
}
}
private List<String> fetchContentBetween(String source, String startRegex, String endRegex, boolean includeEdges) {
List<String> contentList = new ArrayList<>();
Pattern patternStart = Pattern.compile(startRegex);
Pattern patternEnd = Pattern.compile(endRegex);
Matcher matcherStart = patternStart.matcher(source);
Matcher matcherEnd = patternEnd.matcher(source);
int nextStart = 0;
while (matcherStart.find(nextStart)) {
nextStart = matcherStart.end();
if (matcherEnd.find(nextStart)) {
int end = matcherEnd.start();
// log.debug("find content between regex, start:{}, end:{}, startRegex:{}, endRegex:{}", nextStart, end, startRegex, endRegex);
contentList.add(source.substring(includeEdges ? matcherStart.start() : matcherStart.end(), includeEdges ? matcherEnd.end() : matcherEnd.start()));
nextStart = includeEdges ? matcherEnd.end() : matcherEnd.start();
}
}
return contentList;
}
String parseJs(String ruleJs, Map<String, String> params) {
try {
Bindings bindings = engine.createBindings();
for (Map.Entry<String, String> entry : params.entrySet()) {
bindings.put(entry.getKey(), entry.getValue());
}
Object ret = engine.eval(ruleJs, bindings);
if (ret instanceof String) {
return (String) ret;
} else {
return ret.toString();
}
} catch (ScriptException e) {
log.warn("javascript eval with exception", e);
} catch (Exception ex) {
log.warn("parse javascript with exception", ex);
}
return "";
}
@Data
@Builder
public static class ParseRule {
/**
* 提取pdf文本的工具, 二选一: pdfbox spire
*/
String textExtractTool;
/**
* 获取发票单号的regex。 查询上下文是整个PDF文本。
*/
String invoiceNumber;
/**
* 获取发票单号的js语句。注意:只有invoiceNumber没有配置的时候才会使用此内容,可以使用 $pdf 参数,类型是字符串,内容是当前pdf的全部文本
*/
String invoiceNumberByJs;
/**
* 获取发票日期的regex. 查询上下文是整个PDF文本。
*/
String invoiceDate;
/**
* 发票日期的js,使用情况同invoiceNumberByJs
*/
String invoiceDateByJs;
/**
* 获取PO号的regex. 查询上下文是整个PDF文本。
*/
String reference;
/**
* 获取PO号的js,使用情况同invoiceNumberByJs
*/
String referenceByJs;
/**
* 获取总金额的regex. 查询上下文是整个PDF文本。
*/
String totalAmt;
/**
* 获取总金额的js,invoiceNumberByJs
*/
String totalAmtByJs;
/**
* 发票日期的格式,需要解析的时候做转换使用,比如 MM/dd/yyyy or yyyy/MM/dd
*/
String invoiceDateFormat;
/**
* 表开始的regex. 查询上下文是整个PDF文本。
*/
String tableStart;
/**
* 表结束的regex,查询内容是从tableStart开始的内容。
*/
String tableEnd;
/**
* 行开始的regex,查询上下文是 一个表 的内容(用tableStart, tableEnd截取的一个表的内容)
*/
String rowStart;
/**
* 行结束的regex,查询上下文是 一个表的内容 中,rowStart查询到的位置之后
*/
String rowEnd;
/**
* 获取商品数量的索引下标。 这里的上下文是 一行 (用rowStart和rowEnd规则解析出来的一行的内容),
* 将其去掉首位空格,并将里面的多个连续空格转为单个空格后,split(' ')之后的数组下表
* 注意,可以是 负数,类似python中的取法,即 -1表示最后一个, -2表示倒数第二个,以此类推
*/
String qtyIdx;
/**
* 如果qty这一列,仅通过 下标还不好取出来,或者得到最终结果,可以借助该 js内容来执行。
* 可以使用 $row 参数,类型是字符串,内容是当前行规整后(去掉首尾空格,多个连续空格转为单空格)的文本
*
* 注意:只有在qtyIdx没有内容的前提下,才会使用qtyByJs来解析
*/
String qtyByJs;
/**
* 获取price的索引下标。原理同qtyIdx
*/
String priceIdx;
/**
* price的js获取方式,原理同qtyByJs
*/
String priceByJs;
/**
* upc(即自己的item number?)的索引下标 ,原理同qtyIdx
*/
String upcIdx;
/**
* upc的js获取方式,原理同qtyByJs
*/
String upcByJs;
/**
* vendorUpc(即供应商的item code等)的索引下标,原理同qtyIdx
*/
String vendorUpcIdx;
/**
* vendorUpc的js获取方式,原理同qtyByJs
*/
String vendorUpcByJs;
}
}
使用方法
简单展示一下使用方法,后期放到管理平台上将解析规则进行配置即可
String pdfUrl = "对应的pdf文件URL";
ParseRule parseRule = ParseRule.builder()
.invoiceNumber("\\d{2},\\s*20\\d{2}\\s+(\\d+)\\s*")
.invoiceDate("([A-Z][a-z]{2}\\s+\\d{2},\\s*\\d{4})\\s+\\d+")
.invoiceDateFormat("MMM dd,yyyy")
.reference("P\\.O\\s+No\\.\\s+.*\\s+(\\d{10,})")
.totalAmt("謝謝您的支持與惠顧.*Total\\s+\\$([0-9,]+\\.\\d{2})")
.tableStart("Qty\\s+Item\\s+Code.*Amount\\s*")
.tableEnd("\\s*謝謝您的支持")
.rowStart("\\d+\\s+\\b[A-Z0-9\\-]+\\b\\s+")
.rowEnd("([0-9,]+\\.\\d{2}\\s*){2}")
.vendorUpcIdx("1")
.qtyIdx("0")
.priceIdx("-2")
.build();
new InvoiceParser(pdfUrl, parseRule).parse();
输出:
08:11:28.058 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - Parse start *************** pdf url is xxxxxxxxxx
08:11:28.058 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - Current parse rule is InvoiceParser.ParseRule(textExtractTool=pdfbox, invoiceNumber=Invoice\s+#\s+(\d+), invoiceNumberByJs=null, invoiceDate=Date\s+(\d{1,2}/\d{1,2}/\d{4}), invoiceDateByJs=null, reference=P\.O\.\s+Number\s(\d{10,}), referenceByJs=null, totalAmt=Page\s+\d+\s+\$([0-9,]+\.\d{2}), totalAmtByJs=null, invoiceDateFormat=MM/dd/yy, tableStart=DescriptionQTY Price Amount, tableEnd=Page\s+\d+, rowStart=\S+\s, rowEnd=([0-9,]+\.\d{2}\s*){2}, qtyIdx=null, qtyByJs=var arr=$row.split(' '); var ret = parseInt(Math.round(arr[arr.length-1].replaceAll(',','')/arr[arr.length-2].replaceAll(',',''))); ret;, priceIdx=-2, priceByJs=null, upcIdx=null, upcByJs=null, vendorUpcIdx=null, vendorUpcByJs=null)
08:11:28.058 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - Parse main info start
08:11:28.059 [main] WARN com.xxx.central.po.service.parser.InvoiceParser - Can not find anything by regex: P\.O\.\s+Number\s(\d{10,})
08:11:28.059 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - Parse main info end, result is: {InvoiceDateLong=1590735600, InvoiceNumber=2042840, InvoiceDate=5/29/2020, TotalAmt=23158.49, Reference=}
08:11:28.059 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - Parse table contents start
08:11:28.059 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - Parse table contents end, tables count is 2
08:11:28.059 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - Parse rows of one table start
08:11:28.060 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - Parse rows of one table end, rows count is 20
08:11:28.488 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - Parse rows of one table start
08:11:28.488 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - Parse rows of one table end, rows count is 15
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - All table data parsed end, total size is 35
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - The parsed items are:
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=18.15, qty=11}
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=13.44, qty=15}
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=42.00, qty=10}
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=120.00, qty=5}
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=120.00, qty=4}
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=33.60, qty=20}
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=135.00, qty=20}
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=28.08, qty=8}
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=39.00, qty=3}
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=42.00, qty=7}
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=39.00, qty=50}
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=33.60, qty=2}
08:11:28.524 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=84.00, qty=5}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=48.00, qty=2}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=86.40, qty=30}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=86.40, qty=90}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=22.50, qty=10}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=30.00, qty=6}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=38.00, qty=15}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=31.20, qty=10}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=31.20, qty=10}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=31.20, qty=2}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=54.00, qty=4}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=57.00, qty=8}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=52.50, qty=2}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=57.00, qty=3}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=36.00, qty=3}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=45.00, qty=1}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=45.00, qty=8}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=36.00, qty=1}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=36.00, qty=1}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=66.00, qty=2}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=35.00, qty=1}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=46.50, qty=10}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - {price=174.00, qty=3}
08:11:28.525 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - Total usd:23158.49, calculatedTotal:23158.49
08:11:28.526 [main] INFO com.xxx.central.po.service.parser.InvoiceParser - Check total result:true
一些使用技巧
一些注意事项:
1、当表格连续出现的时候(每一页pdf都没有多余的内容,直接是表信息),会出现tableStart和tableEnd相同的情况,这个不用着急,可以正常解析。因为扫描Table信息是(tableStart,tableEnd),不会包含边界 tableStart,所以一个表的tableEnd也可以作为另一个表的tableStart使用。
2、当表的结束符可能是多个的时候(比如连续表格内容,中间的表的tableEnd都是tableStart,但是最后一个tableEnd是其他情况),这个时候,可以试用正则表达式的 “或”,即单个的竖线 | 来表示,比如 “\s+ITEM\s+DESCRIPTION|\s*PO#\s+VI_\d+”
3、 row已经提前处理掉首尾空格(trim), 中间的多个空格转为一个空格,可以放心使用索引下表 (js中, 使用$row.split(’ ')进行列的切分)
4、 一些使用多行文本来筛选内容的正则表达式:tableStart/tableEnd/rowStart/rowEnd/ invoiceNumber/invoiceDate/reference/totalAmt,不能用表示字符串首的 ^ 符号来表示非整个pdf开头的地方,例如:
111111111
2222 333,4444
333232323
上面这个内容,试用^ 只能匹配到第一行的11111111,不会匹配第二行的行首,因为我们是一个整体,并没有按行切分。
5、捕获基础信息,需要用到正则表达式的“捕获分组”功能,比如 INVOICE DATE:\s+([0-9/]+) ,在引擎内部会直接捕获到([0-9/]+)匹配到的内容,因此 规则里面的 invoiceNumber/invoiceDate/reference/totalAmt中,有且只能有一对圆括号
6、totalAmt捕获之后,引擎已经去掉逗号,因此不用担心(别为此使用js去去除)
7、日期格式需要规定,比如是 MM/dd/yyyy还是 yyyy/MM/dd 等
8、js语句中,最后一个表达式,就是返回值。比如 var a = 3;a; 那么获取的是a的值。
9、在后台配置正则表达式规则的时候,使用\d \s这种就行,不要写成\d \s这样的。Java代码中的2个\只是为了转义\本身。
10、一些正则表达式的使用:
1、\s,可以匹配多个空格以及回车换行,很好用,特别是在做多个空行匹配的时候
2、注意特殊字符匹配需要转义,比如 . ( $等 ,需要注意的是, / 不是特殊字符
3、例子中经常用到的行尾的表达: ([0-9,]+\\.\\d{2}\\s*){2} 匹配多个 123.45 2,333.00 这种的,很好用
评论区