

前面写过的一篇博文多语言架构的思考已经提到过多语言架构的一些实现方法和思路。
关于里面提到的案例,这里有其相关的技术实现要点。
这里先提出几个问题:
- 1、如何使用
Google Translation API - 2、如何保持特定内容不翻译(或者翻译为特定内容)
- 3、如何加速(并发)
- 4、富文本问题(价格相关)
- 5、没有
API Gateway怎么办 - 6、瓶颈问题
如何使用Google Translation API
我们默认使用Google Translate API翻译内容,然后可以让运营人员手动更改翻译文本(如果翻译不准确的话),
使用Google Translate API的话,需要有以下几个步骤:
参考这里的官方链接
- 1、创建项目
- 2、启用结算功能
- 3、启用
Cloud Translation API - 4、设置用量配额(可选)
- 5、身份认证
- 6、使用客户端库
前面4点都比较简单,这里主要是说下身份认证问题。
身份认证
创建服务账号:
- 在
Cloud Console中,转到创建服务帐号页面。转到“创建服务帐号”。 - 选择您的项目。
- 在服务帐号名称字段中,输入一个名称。
Cloud Console会根据此名称填充服务帐号 ID 字段。在服务帐号说明字段中,输入说明。例如,Service account for quickstart。 - 点击创建并继续。
- 如需提供对项目的访问权限,请向服务帐号授予以下角色:Project > Owner。在选择角色列表中,选择一个角色。如需添加其他角色,请点击 add 添加其他角色,然后添加其他各个角色。
注意:角色字段会影响您的服务帐号可以访问项目中的哪些资源。您可以撤消这些角色或稍后授予其他角色。在生产环境中,请勿授予 Owner、Editor 或 Viewer 角色。请改为授予满足您需求的预定义角色或自定义角色。
- 点击继续。
- 点击完成以完成服务帐号的创建过程。不要关闭浏览器窗口。您将在下一步骤中用到它。
创建服务帐号密钥:
- 在 Cloud Console 中,点击您创建的服务帐号的电子邮件地址。
- 点击密钥。
- 依次点击添加密钥和创建新密钥。
- 点击创建。**
JSON 密钥文件**将下载到您的计算机上。 - 点击关闭。
使用密钥文件
这里有两个使用方法:
- 1、 使用环境变量设置(推荐使用)
设置好环境变量GOOGLE_APPLICATION_CREDENTIALS为上面下载的JSON密钥文件的位置即可。
如果使用Docker,可以
ADD ./translation-demo-7bee84226539.json /app/translation-certification.json
ENV GOOGLE_APPLICATION_CREDENTIALS=/app/translation-certification.json
- 2、代码中直接读取使用
JSON密钥文件
static void authExplicit(String jsonPath) throws IOException {
// You can specify a credential file by providing a path to GoogleCredentials.
// Otherwise credentials are read from the GOOGLE_APPLICATION_CREDENTIALS environment variable.
GoogleCredentials credentials = GoogleCredentials.fromStream(new FileInputStream(jsonPath))
.createScoped(Lists.newArrayList("https://www.googleapis.com/auth/cloud-platform"));
Storage storage = StorageOptions.newBuilder().setCredentials(credentials).build().getService();
System.out.println("Buckets:");
Page<Bucket> buckets = storage.list();
for (Bucket bucket : buckets.iterateAll()) {
System.out.println(bucket.toString());
}
}
如何保持特定内容不翻译
这里需要使用Google翻译的一个功能: 术语表
参考这里的官方指南
术语表可以预定义一组翻译内容,比如希望英文的Taobao翻译成韩语语还是Taobao,那么就需要设定术语表。
创建术语表需要以下几个步骤:
1、创建CSV文件,例如:
zh-CN,zh-TW,en,ja,ko,es,vi
taobao,taobao,taobao,taobao,taobao,taobao,taobao
支付宝,支付寶,alipay,alipay,alipay,alipay,alipay
public static String makeCvsFile(List<String> headerList, List<List<String>> contentList){
if(CollectionUtils.isEmpty(headerList) || CollectionUtils.isEmpty(contentList)){
return "";
}
if(headerList.size() != contentList.get(0).size()){
throw new RuntimeException("Make csv file but header and content size not equal");
}
StringBuilder sb = new StringBuilder(String.join(",", headerList));
sb.append("\n");
for(List<String> content : contentList){
sb.append(String.join(",", content)).append("\n");
}
return sb.toString();
}
2、上传到google storage
public void updateGlossary(List<String> headerList, List<List<String>> contentList){
String csvContent = Csv.makeCvsFile(headerList, contentList);
GoogleStorageHelper.updateGlossary(csvContent.getBytes(StandardCharsets.UTF_8));
TranslateHelper.updateGlossary();
}
public static void updateGlossary(byte[] content){
Storage storage = StorageOptions.newBuilder().setProjectId(Constants.GOOGLE_PROJECT_ID).build().getService();
BlobId blobId = BlobId.of(Constants.GOOGLE_STORAGE_BUCKET_NAME, Constants.GOOGLE_STORAGE_OBJ_GLOSSARY_NAME);
BlobInfo blobInfo = BlobInfo.newBuilder(blobId).build();
Blob blob = storage.create(blobInfo, content);
}
3、使用上面传到Google Storage的文件,创建术语表资源
public static void updateGlossary(){
deleteGlossary();
createGlossary();
}
public static void deleteGlossary(){
String projectId = Constants.GOOGLE_PROJECT_ID;
String glossaryId = Constants.GOOGLE_TRANSLATE_GLOSSARY_ID;
try {
deleteGlossary(projectId, glossaryId);
}catch (Exception e){
e.printStackTrace();
log.error("delete glossary with exception, " + e.getLocalizedMessage());
}
}
public static void createGlossary(){
String projectId = Constants.GOOGLE_PROJECT_ID;
String glossaryId = Constants.GOOGLE_TRANSLATE_GLOSSARY_ID;
List<String> languageCodes = new ArrayList<>();
languageCodes.add(Constants.LANGUAGE_CODE_ENGLISH);
languageCodes.add(Constants.LANGUAGE_CODE_CHINESE_SIMPLIFIED);
languageCodes.addAll(Constants.EXISTS_LANGUAGE_SET);
String inputUri = Constants.GOOGLE_STORAGE_OBJ_GLOSSARY_PATH;
try {
createGlossary(projectId, glossaryId, languageCodes, inputUri);
}catch (Exception e){
e.printStackTrace();
log.error("create glossary error, " + e.getLocalizedMessage());
}
}
// Create a equivalent term sets glossary
// https://cloud.google.com/translate/docs/advanced/glossary#format-glossary
public static void createGlossary(
String projectId, String glossaryId, List<String> languageCodes, String inputUri)
throws IOException, ExecutionException, InterruptedException {
// Initialize client that will be used to send requests. This client only needs to be created
// once, and can be reused for multiple requests. After completing all of your requests, call
// the "close" method on the client to safely clean up any remaining background resources.
try (TranslationServiceClient client = TranslationServiceClient.create()) {
// Supported Locations: `global`, [glossary location], or [model location]
// Glossaries must be hosted in `us-central1`
// Custom Models must use the same location as your model. (us-central1)
String location = Constants.GOOGLE_TRANSLATE_GLOSSARY_LOCATION;
LocationName parent = LocationName.of(projectId, location);
GlossaryName glossaryName = GlossaryName.of(projectId, location, glossaryId);
// Supported Languages: https://cloud.google.com/translate/docs/languages
Glossary.LanguageCodesSet languageCodesSet =
Glossary.LanguageCodesSet.newBuilder().addAllLanguageCodes(languageCodes).build();
// Configure the source of the file from a GCS bucket
GcsSource gcsSource = GcsSource.newBuilder().setInputUri(inputUri).build();
GlossaryInputConfig inputConfig =
GlossaryInputConfig.newBuilder().setGcsSource(gcsSource).build();
Glossary glossary =
Glossary.newBuilder()
.setName(glossaryName.toString())
.setLanguageCodesSet(languageCodesSet)
.setInputConfig(inputConfig)
.build();
CreateGlossaryRequest request =
CreateGlossaryRequest.newBuilder()
.setParent(parent.toString())
.setGlossary(glossary)
.build();
// Start an asynchronous request
OperationFuture<Glossary, CreateGlossaryMetadata> future =
client.createGlossaryAsync(request);
log.info("Waiting for operation to complete...");
Glossary response = future.get();
log.info("Created Glossary.");
log.info("Glossary name: {}", response.getName());
log.info("Entry count: {}", response.getEntryCount());
log.info("Input URI: {}", response.getInputConfig().getGcsSource().getInputUri());
}
如何加快翻译速度
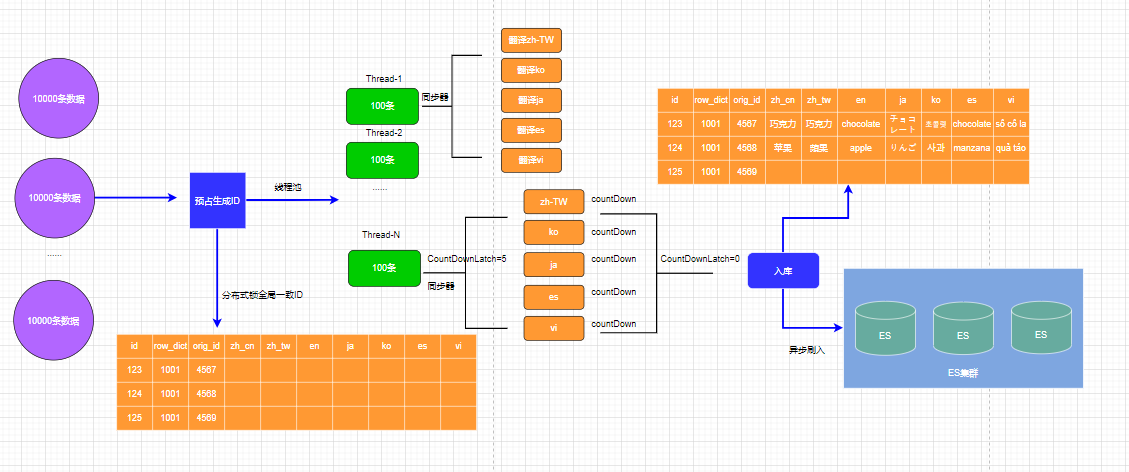
这里说个限制: Google Translate API在批量翻译的时候,会限制传递的List的size,最大为100,也就是一次最多同时翻译100条。每一个请求差不多是1秒左右返回。加上我们翻译5种语言的目标,100条数据,就需要5秒,10000条需要500秒的时间。
很显然,太慢了,需要用多线程做并发请求。
我们可以限制每次扫描使用10000条数据,分割成100组,每组100条数据,这每组的100条数据还需要使用5个线程做同时5种语言的并发请求翻译。所以一共是100*5=500个线程,考虑到线程执行时间,有的还没开始,有的已经结束,加上Google Translate API限制每分钟6000 requests(qpm),我们差不多设定大小为100的一个线程池,是完全够用的。
注意:为了方便以及高效,同一个内容翻译的5个结果全部返回后,才往数据库里面写入数据(不是每次返回就写),这里可以用CountDownLatch来做统一等待处理。
![]()
上面这个在一次批量处理10000条数据是高效统一的,不过如果是分布式部署,比如Docker compose/swarm或者K8s集群多pod部署,那么需要考虑数据库ID自动插入的时候不冲突。这个时候需要提前用分布式锁做ID预占处理,保证全局ID映射的有序性、有效性。
![]()
上面的
row_dict_id为原始库/表/字段的一个字典,比如row_dict_id为1001表示原 mydb.mytable.goods_name_en。orig_id表示这条字段在原表里面的主键id。
富文本问题
Google翻译是按照字符来收费的
| 按流量计费的用量 | 价格 |
|---|---|
| 每月前 50 万个字符* | 免费(每月用 $10 赠金支付)† |
| 每月 50 万到 10 亿个字符* | 每 100 万个字符 $20# |
| 每月超过 10 亿个字符* | 请与销售代表联系商谈折扣价格。 |
我们测试翻译
20w条数据的商品名称,翻译为5种语言,大约消耗了$1000
当我们需要翻译成多种语言的时候,成本是成倍增加的。
如果是富文本,例如下面这个:
<p class="p1"><span class="s1"><span class="Apple-converted-space"> </span></span></p>
<p class="p2"><span class="s1"></span><br></p>
<p class="p2"><span class="s1"></span><br></p>
<p class="p3"><span class="s2">??</span><span class="s3">This one is in the process of rolling, one side has been rolled, it is a little messy, and the length Much shorter than straight hair. </span></p>
<p class="p2"><span class="s1"></span><br></p>
<p class="p2"><span class="s1"></span><br></p>
我们本来只需要翻译This one is in the process of rolling, one side has been rolled, it is a little messy, and the length Much shorter than straight hair.这句话,一共100个字符左右,但是如果是整个富文本HTML内容全部翻译,就是1000个字符左右,成本翻了10倍!
那如何优化呢?
思路:
1、将富文本种的纯文本提取出来
2、用特殊字符分隔,需要保证Google Translate API不会翻译它
3、完成后,按照提取的方式,进行回填
具体代码如下:
/**
* HTML中原生的空格表示  
*/
public static final String HTML_SPACE_STR_RAW = " ";
/**
* 转义之后的 jsoup在给TextNode写入 text内容有 &时,会转义
*/
public static final String HTML_SPACE_STR_RAW_ESCAPE = "&nbsp;";
/**
* 用于替换原生空格的 预定义Glossary <n>
*/
public static final String HTML_SPACE_STR_REPLACEMENT = "<n>";
/**
* HTMl中文本的分隔符,预定义Glossary <k> ,不会被翻译,用于切分
*/
public static final String HTML_STATEMENT_SPLITTER = "<k>";
/**
*
* @param ele 元素
* @param sb 查找时使用的容器
* @param translatedList 翻译的内容,回填时候的容器
* @param fillBack 是否是回填数据
*/
public static void visit(Element ele, StringBuilder sb, LinkedList<String> translatedList, boolean fillBack){
for(Node node : ele.childNodes()) {
if(node instanceof TextNode) {
if (fillBack) {
//check index
if (translatedList.size() > 0){
String translatedStr = translatedList.remove(0);
((TextNode)node).text(translatedStr.replaceAll(HTML_SPACE_STR_REPLACEMENT, HTML_SPACE_STR_RAW));
}
} else {
sb.append(node.outerHtml().replaceAll(HTML_SPACE_STR_RAW, HTML_SPACE_STR_REPLACEMENT)).append(HTML_STATEMENT_SPLITTER);
}
}
if(node instanceof Element){
visit((Element) node, sb, translatedList, fillBack);
}
}
}
/**
* 从富文本中获取需要翻译的内容,主要用于去除不需要的各种html标签字符(翻译这些需要浪费大量钱的)
* @param html 原始的富文本内容
* @return 需要翻译的内容(去除标签,添加特殊字符)
*/
public static String getContentFromRichText(String html){
if(StringUtils.isNullOrEmpty(html)){
return "";
}
Document document = Jsoup.parse(html);
StringBuilder stringBuilder = new StringBuilder();
visit(document.root(), stringBuilder, new LinkedList<>(), false);
String ret = stringBuilder.toString();
String[] r = ret.split(HTML_STATEMENT_SPLITTER);
log.info("find count :" + r.length);
return ret;
}
/**
* 用已翻译文本来更新富文本
* @param html 原始的富文本
* @param translatedText 翻译结果
* @return 更新后的富文本
*/
public static String updateRichTextWithTranslatedText(String html, String translatedText){
if(StringUtils.isNullOrEmpty(html)){
return "";
}
//TODO 可以考虑复用上面方法的 Document对象
Document document = Jsoup.parse(html);
LinkedList<String> retList = Arrays.stream(translatedText.split(HTML_STATEMENT_SPLITTER)).collect(Collectors.toCollection(LinkedList::new));
log.info("update count: " + retList.size());
visit(document.root(), new StringBuilder(), retList, true);
return Objects.requireNonNull(document.selectFirst("html")).html().replaceAll(HTML_SPACE_STR_RAW_ESCAPE, HTML_SPACE_STR_RAW);
}
翻译的时候使用术语表来翻译。
public static List<String> translateTextWithGlossary(
String projectId,
String sourceLanguage,
String targetLanguage,
List<String> textList,
String glossaryId,
boolean isHtml
)
throws IOException {
// Initialize client that will be used to send requests. This client only needs to be created
// once, and can be reused for multiple requests. After completing all of your requests, call
// the "close" method on the client to safely clean up any remaining background resources.
List<String> result = new ArrayList<>(textList.size());
try (TranslationServiceClient client = TranslationServiceClient.create()) {
// Supported Locations: `global`, [glossary location], or [model location]
// Glossaries must be hosted in `us-central1`
// Custom Models must use the same location as your model. (us-central1)
String location = Constants.GOOGLE_TRANSLATE_GLOSSARY_LOCATION;
LocationName parent = LocationName.of(projectId, location);
GlossaryName glossaryName = GlossaryName.of(projectId, location, glossaryId);
TranslateTextGlossaryConfig glossaryConfig =
TranslateTextGlossaryConfig.newBuilder().setGlossary(glossaryName.toString()).build();
// Supported Mime Types: https://cloud.google.com/translate/docs/supported-formats
TranslateTextRequest request =
TranslateTextRequest.newBuilder()
.setParent(parent.toString())
.setMimeType(isHtml ? "text/html" : "text/plain")
.setSourceLanguageCode(sourceLanguage)
.setTargetLanguageCode(targetLanguage)
.addAllContents(textList)
.setGlossaryConfig(glossaryConfig)
.build();
TranslateTextResponse response = client.translateText(request);
// Display the translation for each input text provided
for (Translation translation : response.getGlossaryTranslationsList()) {
log.debug("translation result :{}", translation.getTranslatedText());
result.add(translation.getTranslatedText());
}
}
return result;
}
这里有几个注意事项:
- 1、对于
越南语,Google Translate API自动添加各种空格(越南语特色?),将里面的 翻译为 & nbsp;也就是多了空格,所以我这里将 全部用替换 - 2、Google Translate API绝大多数情况不会翻译标签,但是也有个别现象。所以为了保持一致,
一定要用术语表,规定<n> <k>等,就翻译为其他语言的<n> <k>等 - 3、
JSoup在设置TextNode的text时,直接写入 会将&转义为&那么 就转义为&bsp;所以需要在updateRichTextWithTranslatedText最后,再将&bsp;转译为 - 4、标记类型的术语表需要配合
MimeType为text/html才行。如果按照官方使用默认的text/plain的话,标签类的术语表可能失效。比如设计了上面的术语表(英文的翻译为其他语言的 ),可能会出现特殊情况把 也翻译掉的情况。如果设定为 text/html就不会,默认针对有标签的内容处理,术语表的也能保持住。
没有API Gateway的情况下怎么做?
我们在之前的文章中提到了,实现这个架构,需要用到一个统一的API Gateway做集中处理。那,如果公司发展还没到使用API Gateway的地步怎么办呢?
可以用AOP代替,写一个公共的AOP库类,给每个项目的pom.xml中集成即可,无需代码调用。
这里的
AOP有点类似Service Mesh里面的Sidecar的思想,代理转发过滤每个Service的流量,进行必要的处理
两步走:
- 1、使用
Filter对全局输出进行过滤 - 2、发现有内容为
i18n##xxx##开头的,表示需要进行转换,调用I18N Service转换即可。
下面是注册Filter代码:
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurerAdapter;
import java.util.ArrayList;
import java.util.List;
/**
*
* Pay attention, we need the project use [apollo config] to fetch the value of
* i18nTranslationurl, or it will be null forever
*/
@Configuration
@Slf4j
public class WebConfig extends WebMvcConfigurerAdapter {
private static String i18nTranslationUrl;
@Value("${i18n_translation_url}")
public void setI18nTranslationUrl(String url){
i18nTranslationUrl = url;
log.info("set i18n translation url = " + url);
}
public static String getI18nTranslationUrl(){
return i18nTranslationUrl;
}
@Bean
public FilterRegistrationBean i18nFilter() {
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean();
I18nFilter i18nFilter = new I18nFilter();
filterRegistrationBean.setFilter(i18nFilter);
List<String> urls = new ArrayList<>();
urls.add("/*");
filterRegistrationBean.setUrlPatterns(urls);
return filterRegistrationBean;
}
}
下面是具体的Filter逻辑:
@Slf4j
public class I18nFilter implements Filter {
private final static String I18N_PREFIX = "i18n##";
private final static String LANGUAGE_EN = "en";
public static final String LANGUAGE_CN = "cn";
public static final String LANGUAGE_CODE_CHINESE_TRADITIONAL = "tw";
public static final String LANGUAGE_CODE_JAPANESE = "ja";
public static final String LANGUAGE_CODE_KOREAN = "ko";
public static final String LANGUAGE_CODE_SPANISH = "es";
public static final String LANGUAGE_CODE_VIETNAMESE = "vi";
public static final Set<String> EXISTS_LANGUAGE_SET = new HashSet<>();
static {
EXISTS_LANGUAGE_SET.add(LANGUAGE_CODE_JAPANESE);
EXISTS_LANGUAGE_SET.add(LANGUAGE_CODE_KOREAN);
EXISTS_LANGUAGE_SET.add(LANGUAGE_CODE_VIETNAMESE);
EXISTS_LANGUAGE_SET.add(LANGUAGE_CODE_SPANISH);
EXISTS_LANGUAGE_SET.add(LANGUAGE_CODE_CHINESE_TRADITIONAL);
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest originalRequest = (HttpServletRequest) servletRequest;
HttpServletResponse originalResponse = (HttpServletResponse) servletResponse;
log.info("i18n filter start url " + originalRequest.getRequestURL());
String contentType = originalRequest.getContentType();
ModifyResponseBodyWrapper responseWrapper = getHttpResponseWrapper(originalResponse);
filterChain.doFilter(servletRequest, responseWrapper);
long timeStart = System.currentTimeMillis();
//消费的是 wrapper里面的数据
String originalResponseBody = responseWrapper.getResponseBody();
@Cleanup ServletOutputStream out = originalResponse.getOutputStream();
log.info("i18n filter after doFilter, content type " + originalResponse.getContentType());
String language = originalRequest.getHeader("target_language");
if (!originalResponseBody.contains(I18N_PREFIX)) {
out.write(originalResponseBody.getBytes(responseWrapper.getCharacterEncoding()));
return;
}
if (language == null || "".equals(language) || !EXISTS_LANGUAGE_SET.contains(language)) {
//表示有 i18n## 字符串,但没有给出语言,我们默认是英语
language = LANGUAGE_EN;
}
try {
JSONObject jsonMap = JSON.parseObject(originalResponseBody);
Set<String> needToTranslateSet = new HashSet<>();
findI18nValue(jsonMap, needToTranslateSet);
Map<String, String> translatedMap = new HashMap<>(needToTranslateSet.size());
try {
//en goes to default logic, cut down the i18n head like i18n##76843##
if (!language.equals(LANGUAGE_EN) && !language.equals(LANGUAGE_CN)) {
Set<String> cachedIdSet = fillByLocalCache(language, needToTranslateSet, translatedMap);
needToTranslateSet.removeAll(cachedIdSet);
if (needToTranslateSet.size() > 0) {
//请求i18n服务,拿到数据,生成新的response
Map<String, String> headerMap = new HashMap<>(2);
headerMap.put("target_language", language);
headerMap.put("Content-Type", "application/json");
RequestBody requestBody = new RequestBody(needToTranslateSet);
String body = HttpClientUtil.doPost(WebConfig.getI18nTranslationUrl(), headerMap, JSON.toJSONString(requestBody));
if (body != null) {
JSONObject bodyJson = JSON.parseObject(body);
String finalLanguage = language;
((JSONObject) bodyJson.get("body")).forEach((key, value) -> {
translatedMap.put(key, (String) value);
updateLocalCache(finalLanguage, key, (String) value);
});
}
}
}
log.info("I18n Filter time used: " + (System.currentTimeMillis() - timeStart));
} catch (Exception e) {
log.error("Error when do with i18n filter " + e.getLocalizedMessage());
}
fillI18nValue(jsonMap, translatedMap);
String modifyResponseBody = jsonMap.toJSONString();
byte[] newResponseData = modifyResponseBody.getBytes(responseWrapper.getCharacterEncoding());
originalResponse.setContentLength(newResponseData.length);
out.write(newResponseData);
out.write(originalResponseBody.getBytes(responseWrapper.getCharacterEncoding()));
} catch (Exception e) {
log.error("Error when do with i18n filter2 " + e.getLocalizedMessage());
out.write(originalResponseBody.getBytes(responseWrapper.getCharacterEncoding()));
}
}
/**
* 从本地cache中获取翻译内容
*
* @param language 语言
* @param idSet 需要翻译的id set
* @param translatedMap 如果存在,附带给该map填充内容
* @return 已存在的id Set
*/
private Set<String> fillByLocalCache(String language, Set<String> idSet, Map<String, String> translatedMap) {
Set<String> cachedSet = new HashSet<>();
for (String id : idSet) {
String key = makeLocalKey(id, language);
String value = LocalCache.get(key);
if (StringUtils.isEmpty(value)) {
continue;
}
cachedSet.add(id);
translatedMap.put(id, value);
}
log.info("findByLocalCache original size is " + idSet.size() + " cachedSize is " + cachedSet.size());
return cachedSet;
}
/**
* 更新本地缓存
*
* @param language 语言
* @param id 已经翻译的 id
* @param value content
*/
private void updateLocalCache(String language, String id, String value) {
if (id != null) {
String key = makeLocalKey(id, language);
LocalCache.put(key, value);
}
}
private String makeLocalKey(String id, String language) {
return id + "#" + language;
}
/**
* extract 11723 from i18n##11723##the_real_content
*
* @param str
* @return
*/
private String extractI18nId(String str) {
int idEndIndex = str.indexOf("#", I18N_PREFIX.length());
return str.substring(I18N_PREFIX.length(), idEndIndex);
}
/**
* extract the_real_content from i18n##11723##the_real_content
*
* @param str
* @return
*/
private String getEnglishContent(String str) {
int idEndIndex = str.indexOf("#", I18N_PREFIX.length());
return str.substring(idEndIndex + 2);
}
private void findI18nValue(JSONObject jsonObject, Set<String> needToTranslateSet) {
jsonObject.forEach((key, value) -> {
if (value instanceof String) {
if (((String) value).startsWith(I18N_PREFIX)) {
needToTranslateSet.add(extractI18nId((String) value));
}
} else if (value instanceof JSONObject) {
findI18nValue((JSONObject) value, needToTranslateSet);
} else if (value instanceof JSONArray) {
findI18nValue((JSONArray) value, needToTranslateSet);
}
});
}
private void findI18nValue(JSONArray jsonArray, Set<String> needToTranslateSet) {
jsonArray.forEach(o -> {
if (o instanceof JSONObject) {
findI18nValue((JSONObject) o, needToTranslateSet);
} else if (o instanceof JSONArray) {
findI18nValue((JSONArray) o, needToTranslateSet);
} else if (o instanceof String) {
if (((String) o).startsWith(I18N_PREFIX)) {
needToTranslateSet.add(extractI18nId((String) o));
}
}
});
}
private void fillI18nValue(JSONObject jsonObject, Map<String, String> translatedMap) {
Set<String> keySet = jsonObject.keySet();
for (String key : keySet) {
Object value = jsonObject.get(key);
if (value instanceof String) {
if (((String) value).startsWith(I18N_PREFIX)) {
String id = extractI18nId((String) value);
if (translatedMap.containsKey(id) && !StringUtils.isEmpty(translatedMap.get(id))) {
jsonObject.put(key, translatedMap.get(id));
} else {
//use english default, but cut down the head: i18n##11123##
jsonObject.put(key, getEnglishContent((String) value));
}
}
} else if (value instanceof JSONObject) {
fillI18nValue((JSONObject) value, translatedMap);
} else if (value instanceof JSONArray) {
fillI18nValue((JSONArray) value, translatedMap);
}
}
}
private void fillI18nValue(JSONArray jsonArray, Map<String, String> translatedMap) {
for (int i = 0; i < jsonArray.size(); i++) {
Object value = jsonArray.get(i);
if (value instanceof String) {
if (((String) value).startsWith(I18N_PREFIX)) {
String id = extractI18nId((String) value);
if (translatedMap.containsKey(id) && !StringUtils.isEmpty(translatedMap.get(id))) {
jsonArray.set(i, translatedMap.get(id));
} else {
jsonArray.set(i, getEnglishContent((String) value));
}
}
} else if (value instanceof JSONObject) {
fillI18nValue((JSONObject) value, translatedMap);
} else if (value instanceof JSONArray) {
fillI18nValue((JSONArray) value, translatedMap);
}
}
}
@Override
public void destroy() {
}
public static ModifyResponseBodyWrapper getHttpResponseWrapper(ServletResponse response) {
HttpServletResponse originalResponse = (HttpServletResponse) response;
return new ModifyResponseBodyWrapper(originalResponse);
}
}
上面代码中,利用递归进行i18n相关的内容查找以及回填。
另外,还有一些本地缓存处理(瓶颈点一定要做多级缓存,我的I18N Service中还有多级缓存,这里的AOP工具是最终要嵌入、伴随着各个业务项目的,所以只做了一些本地缓存)。
瓶颈问题
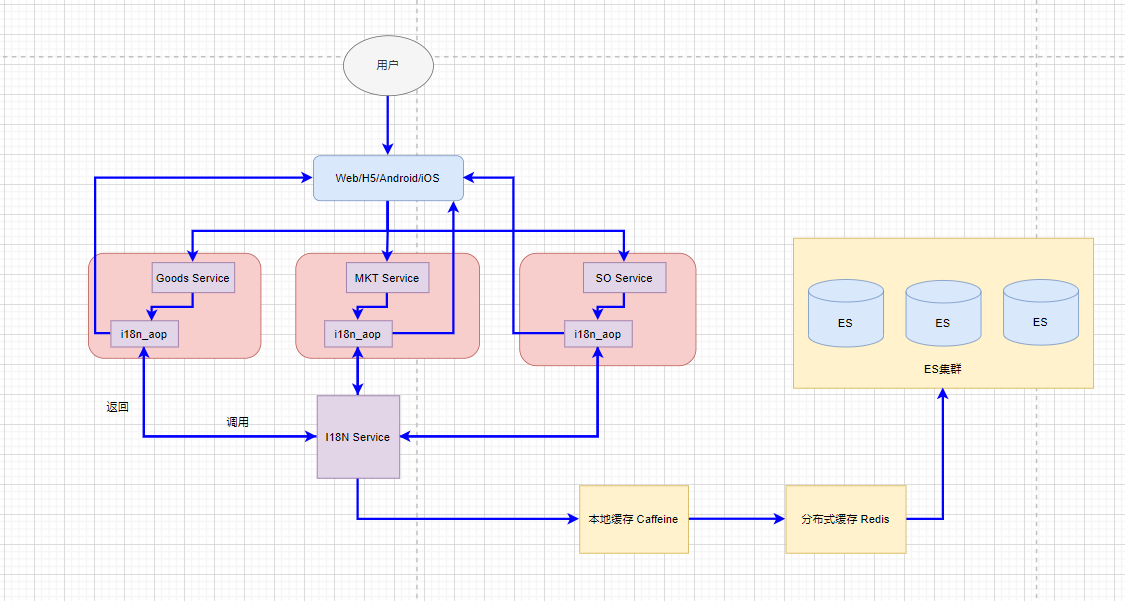
如果是上面单纯的单表做整个公司全部业务数据的多语言存储,很显然是不现实的,这里需要使用一些其他存储体系。
考虑到我们只是简单的存取,并没有业务逻辑在里面,可选的范围很大:
- 各种Key-Value存储
- 列式存储(可能底层还是Key-Value存储)
- ElasticSearch
除了修改存储/持久化之外,还需要多级缓存,保证读取速度。
- 使用本地存储(各个JVM实例中均保留一份)
- 使用分布式存储(redis)
这里我们可以看看使用常见的ElasticSearch作为存储的情况。
首先是前面的架构图,在写入DB(做终极持久备份,但是不用在查询上)的时候,异步写入ElasticSearch
然后是I18N Service,这里采用前面AOP的方式替代API Gateway,在每个AOP(这么个sidecar)中,调用I18N Service,I18N Service从多级缓存中依次取数据,最终访问到ES集群。
结束语
上面只是一个可能的解决方法,本人能力有限,如有不合理的地方,欢迎指正。
评论区